通用人工智能什么时候实现,自今年清北强强联合举办通人工智能实验班之后,我国通用人工智能领域的研究开始广受大家的关注,大家最好奇的一点是通用人工智能什么时候才能够实现,小编收录整理了一些信息,供大家参考。
通用人工智能什么时候实现
在 2015 年,笔者对通用人工智能何时能够实现做出了以下预测:
到 2045 年,有 10% 的可能性。
到 2050 年,有 50% 的可能性。
到 2070 年,有 90% 的可能性。
现在已经是 2020 年了,笔者将预测更新为如下:
到 2035 年,有 10% 的可能性。
到 2045 年,有 50% 的可能性。
到 2070 年,有 90% 的可能性。
笔者将 90% 的可能性的年份保持不变,但将其他一切都调得更快了。现在,如果你想知道笔者为什么选择这些特定的年份,以及为什么笔者用 10 年而不是 5 年或 15 年来改变,你将会失望的。因为这些都是笔者靠直觉进行预测的。重要的是为什么笔者的部分想法发生了变化——你可以在这个基础上,选择自己的时间轴进行调整。

让笔者们先从简单的部分开始。
笔者应该更不确定
如果说,笔者从来没有对机器学习的研究感到惊讶,那将是一件不可思议的怪事。从历史上看,预测一个研究领域的发展轨迹是很难的。如果笔者从来没感到惊讶,笔者会认为这是由于笔者个人没有考虑足够大的想法所致。
同时,当笔者回想起过去的五年,笔者相信笔者比平常更感到惊讶。并不是所有的事情都朝着积极的方向发展。无监督学习比笔者想象的要好得多。深度强化学习比笔者预期的要好一些。而迁移学习比笔者想的要慢一些。综合起来,笔者决定扩大结果的分配范围,所以,现在笔者把 35 年的时间分配到 10% ~ 90% 的时间间隔,而不是 25 年。
笔者还注意到,笔者在 2015 年的预测将 10% ~ 50% 放在 5 年的范围内,50% 到 90% 放在 20 年的范围内。通用人工智能是一个长尾事件,确实有可能永远不可行,但 5 ~ 20 的拆分显然是不科学的。笔者正在相应地调整。
现在,笔者们到了最难的部分。为什么笔者选择将 10% 和 50% 的年份更靠近现在呢?
笔者没有考虑到更好的工具
三年前,笔者曾和一个人聊天,他提到 通用人工智能没有“火警警报”。笔者告诉他们,笔者知道 Eliezer Yudkowsky 写了另一篇关于通用人工智能的文章,笔者还注意到 Facebook 的朋友们分享了这篇文章,但笔者还没有来得及阅读。他们将这篇文章总结为:“通用人工智能何时发生,永远不会很明显。即使是在它发生前几年,人们也会认为通用人工智能还很遥远。等到大家都认识到人工智能安全是世界上最重要的问题时,就已经太晚了。
笔者的反应是,“好吧,这和笔者从 Facebook 的时间轴上得到的信息相符。就在费米参加曼哈顿计划前几年,笔者就已经知道 费米预测核连锁反应很可能是不可能 的。最近,Rémi Coulom 表示,超人类的围棋程序大约还有 10 年时间,一年后才出现 最初的可能迹象,两年后,AlphaGo 正式问世。笔者也已经知道人工智能安全的 常识>) 观点。”笔者觉得这篇文章不值得花时间去阅读。
(如果你还没有听过这些常识的争论,下面是简短版:大多人认为人工智能安全是值得的,即使没有人公开这么说,因为每个人都可能担心,如果他们主张采取激烈行动,其他人就会说他们疯了。即使每个人都同意,这种情况也可能发生,因为他们不知道每个人都同意。)
几年后,出于无聊,笔者重新阅读了这篇文章,现在笔者得向 Facebook 上那些只分享历史事件和常识的好友们抱怨了。尽管那篇帖子的总结是正确的,但是,笔者发现有用的想法都在总结之外。笔者是那么信任你,你就不能把泡沫过滤掉吗?你怎么可以这样让笔者失望呢?
那篇“火警警报”的帖子中的一部分提出了一些假设,解释了为什么人们声称通用人工智能是不可能的。其中一个假设是,研究人员过于关注使用现有工具进行工作的难度,并将这种难度推断到未来,得出结论:笔者们永远不可能创造出通用人工智能,因为现有的工具还不够好。这是个槽糕的论点,因为你的推断也需要考虑到研究工具也随着时间的推移而改进。
“工具”的意思有点模糊。一个明显的例子是笔者们的编码库。在过去,人们用 Caffe、MATLAB 和 Theano 来编写神经网络,而现在主要是 TensorFlow 和 PyTorch。一个不太明显的例子是用于计算机视觉的特征工程。最后一次有人谈论计算机视觉的 SIFT 特征 是什么时候?那是好多年以前,它们现在已经过时了。但特征工程并没有消失,只是变成了 卷积神经网络 的架构调优。对于计算机视觉研究者来说,SIFT 特征是老旧的工具,卷积神经网络则是崭新的工具,而计算机视觉是被更好的工具所强化的应用。
然而对笔者来说,笔者并不是计算机视觉专家。笔者认为用于控制的机器学习是一个更有趣的问题。但是,在基于图像的环境中,你必须进行计算机视觉来进行控制,如果你想处理现实世界,基于图像的输入是最好的选择。所以对笔者来说,计算机视觉是工具,机器人是应用,计算机视觉的进步推动了许多有前途的机器人学习成果。

[AlexNet](https://en.wikipedia.org/wiki/AlexNet) 自动学习的过滤器,而 AlexNet 本身已被更好的工具 [ResNet](https://en.wikipedia.org/wiki/Residual_neural_network) 淘汰了。
笔者是研究工具的大力支持者。笔者认为就平均而言,人们低估了它们的影响力。因此,在阅读了人们不能正确预测工具改进的假设之后,笔者进行了思考,认为自己也没有正确地解释它。那应该被砍掉几年。
在机器学习更多的经验方面,进展的明显组成部分是你的想法和计算预算,但也有一些不那么明显的,比如,你的编码和调试技能,以及你使用计算机的能力。如果代码没有使用所有可用的处理器,那么每台计算机有多少个处理器就并不重要。有很多令人惊讶的机器学习应用,主要的增值来自己于更好的数据管理和数据汇总,因为这些工具可以腾出决策时间来做其他事情。
一般来说,每个人的研究工具都有一定的缺陷。研究是为了做一些新的事情,自然也就会发现新的问题,为了解决三个月前还不存在的问题,人们就做出了完美的工具,这不太可能。因此,你现在的研究工具总是会让人感觉不太好用,你就不应该用它来争论什么时间轴的问题。
研究栈有很多部分,整个栈中有不断的改进,而且这些改进中的大多数都有乘法效应。乘数因素可以非常强大。一个简单的例子是,要获得 10 倍的更好结果,你可以通过范式转换将一件事改进 10 倍,或者可以将 10 件不同的事情 改进 1.26 倍,它们加起来可以得到 10 倍的总体改进。后者同样具有变革性,但可能要容易得多,特别是你让 10 位拥有不同技能的专家为了一个共同目标而合作的时候。这就是企业如何成就一件事情的秘诀。
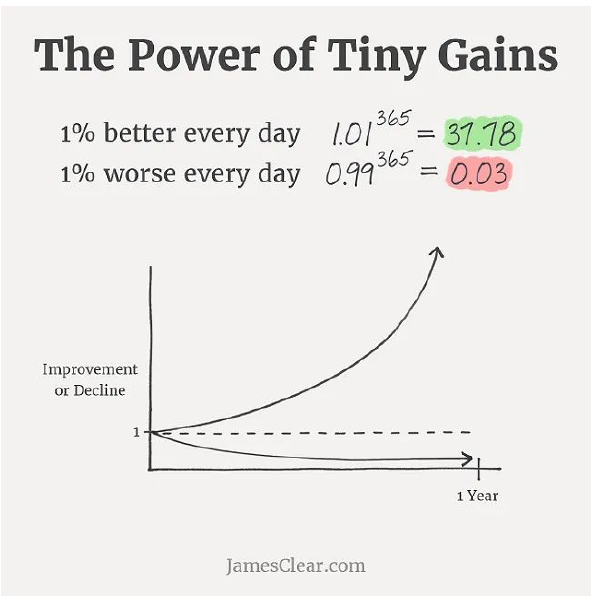
半监督和无监督学习正变得越来越好
从历史上来看,无监督学习一直处于这种奇怪的位置,它显然是正确的学习方式,但如果你想让某件东西尽快发挥作用,这也完全是在浪费时间。
一方面,人类学习的大多数东西都没有标签,所以机器学习系统也不应该需要什么标签。另一方面,2015 年的深度学习热潮主要是由带标签的大型数据集上的监督学习所推动的。当时,Richard Socher 在推特上发布了一条引人入目的 推文:
与其花一个月的时间去琢磨一个无监督机器学习的问题,还不如用一个礼拜的时间给一些数据贴上标签,然后训练一个分类器。
—— Richard Socher (@RichardSocher),2017 年 3 月 10 日
笔者不会说无监督学习一直没用。在 2010 年,人们普遍认为,深度学习在开始监督式学习之前,应该先经过一个无监督的预训练步骤。参见 Erhan 等人在 JMLR 2010 发表的论文《为什么无监督的预训练有助于深度学习?》(Why Does Unsupervised Pre-training Help Deep Learning?)。2015 年,像 GloVe 和 word2vec 这样的自笔者监督词向量可以自动学习词汇之间的有趣关系。作为一个 2015 年左右开始机器学习的人,这些无监督学习的成功感觉就像是规则的例外。大多数其他应用都依赖于标签。预训练的 ImageNet 特征是最接近一般行为的东西,这些特征是通过监督式学习从头开始学习的。
笔者一直都认为,无监督学习是未来的趋势,也是正确的方式,只要笔者们弄清楚如何去实现。但是,伙计,笔者们已经花了很长时间来尝试实现。这让笔者对过去几个月的半监督学习和无监督学习的论文印象深刻。Momentum Contrast(He 等人,VCPR 2020)相当不错,SimCLR(Chen 等人,ICML 2020)在此基础上有所改进,Bootstrap Your Own Latent(Grill、Strub、Altché、Tallec、Richemond 等人,2020 年)在此基础上也有所改进,然后是 GPT-3,这个笔者待会儿再讲。
当笔者在思考是什么让机器学习变得困难时,趋势线指向更大的模型和更大的标记数据集。它们现在还在指那个方向。笔者的结论是,未来的机器学习进展将受到标签要求的瓶颈。定义一个 10 倍大的模型很容易,而训练一个 10 倍大的模型却更难,但它并不需要 10 倍多的人来工作。获得 10 倍的标签就可以了。是的,数据标签工具会越来越好,Amazon Mechanical Turk 非常受欢迎,甚至有一些创业公司的使命就是提供快速的数据标签服务。但标签本质上就是关于人类偏好的问题,这就很使它难逃脱人类的劳动。
强化学习的奖励功能也有类似的问题。原则上,在你定义什么是成功后,模型就会找到解决方案。实际上,你需要一个人来检查模型是否正在“黑掉”奖励,或者你的奖励函数是由人类评级者隐形定义的,这就变成了同样的标签问题。
带标签的大型数据集不会平白无故地出现。它们需要深思熟虑的、持续的努力才能产生。ImageNet 能够在 CVPR 2019 上获得时间测试奖 不是没有原因的——那篇论文的作者发表并完成了这项工作。如果机器学习需要更大的标记数据集来推动性能,并且模型不断以数量级保持增长,那么你就会到达一个这样的临界点,取得进展所需的人类监督量将是疯狂的。
(这甚至还没有涉及到标签不完美的问题。笔者们发现,在流行的基准测试中使用的许多有标签的数据集就包含了大量的偏见。这并不奇怪,但现在它已经越来越接近常识,用自由放任的标签系统构建一个大型数据集,将不再可行。)
好吧,嗯,如果 10 倍的标签是个问题,那有没有办法绕过这个问题呢?一种方法是,如果你不需要 10 倍的标签来训练一个 10 倍大的模型。关于这方面的信息挺复杂的。一篇标度律(Scaling law)的论文(Hestness 等人,2017 年)建议模型大小随数据集大小次线性(sublinearly)增长。
笔者们期望拟合一个数据集的模型参数的数量应该遵循 $s(m) \propto \alpha m^{\beta_p}$,其中 $s(m)$ 是一个拟合一个大小为 $m$ 的训练集所需的模型大小。
不同的问题设置具有不同的悉数,图像分类遵循 $\beta_p=0.573$ 幂定律,而语言建模遵循 $\beta_p \approx 0.72$ 线。
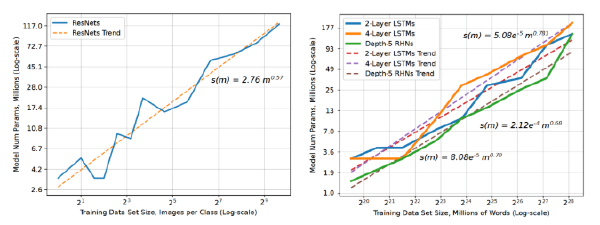
图像分类趋势线(左)和语言建模趋势线(右)([来源:Hestity 等人,2017 年](https://arxiv.org/abs/1712.00409))
反过来说,这意味着数据集大小应随模型大小呈超线性增长:10 倍大的图像分类模型应该使用 $10^{1/0.573} = 55.6$ 倍的数据!那真是个可怕的消息啊!
但是,Kuplan 和 Candlish 在 2020 年发表的论文 却提出了相反的关系:数据集的大小应该随着模型的大小而增长。他们只研究语言建模,但是在论文的第 6.3 节指出:
为控制过拟合,第 4 节的结果暗示笔者们应该将数据集的大小扩展为 $D \propto N^{0.74}$,其中 $D$ 是数据集大小,$N$ 是模型大小。
与 $D \propto N^{1/0.72}$ 的 Hestness 结果相比,这显得很奇怪。数据集应该比模型增长得快还是慢呢?
这两个数字之间存在差异的原因是,Kaplan 结果是在假设固定的计算预算的情况下得出的。他们发现的一个关键结果是,在短时间内训练一个非常大的模型比训练一个较小的模型来收敛效率更高。同时,据笔者所知,Hestness 结果总是使用训练过的模型来收敛。
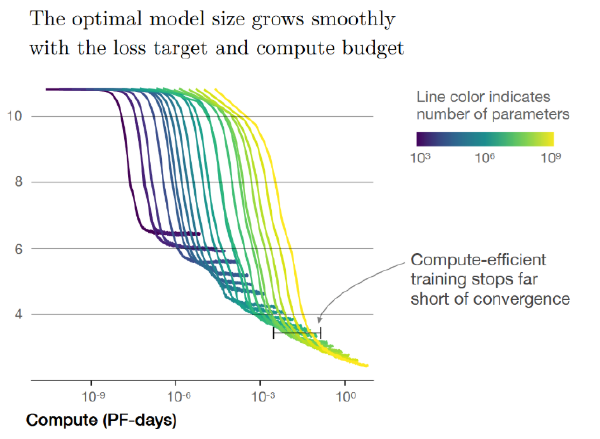
来源:[Kaplan 和 Candlish,2020 年](https://arxiv.org/abs/2001.08361)
这有点离题了,但是输入数字之后,笔者们得到模型大小每增加 10 倍,数据集大小就需要增加 4 到 50 倍。让笔者们假设 4 倍的方面要大方。对于标签需求而言,4 倍的系数肯定要比 10 倍的系数好很多,但仍然是很多。
进入无监督学习,这些方法正在变得越来越好,“标签”的意义正朝着更容易获得的方向发展。GPT-3 是在一堆网络抓取数据上进行训练的,虽然也需要一些输入处理,但在进入模型训练之前,它并不需要人工验证文本的每一句话。在足够大的规模下,尽管看起来你的标签是嘈杂的,数据是混乱的,但这都是可以的。
这里有很大的潜力。如果你有 $N$ 个无监督的例子,那么 $N$ 个带标签的例子会更好,但要记住,标签是需要花费很多精力的。标记数据集的大小受你所能承担的监督的限制,并且你可以用同样的工作量获得更多的无标签数据。
很多有关大数据的炒作都是由一些情节驱动的,这些情节显示数据的创造速度比摩尔定律还快。大肆炒作最终还是失败了,因为无知的高管不明白这一点:拥有数据与拥有有用的机器学习并不是一回事。可用数据的真实数量要少得多。这引起了研究界的哄笑,但如果无监督学习变得更好,甚至垃圾数据也变得稍微有用的话,那么笔者们就会成为笑柄。
无监督学习已经足够好了吗?当然没有,100% 绝对没有。这比笔者预期的要近。笔者希望看到更多的论文使用与目标任务无关的数据源,以及更多的“ImageNet 时刻”,通过“站在别人 GPU 时间的肩膀上”来构建应用。
GPT-3 的结果在质量上比笔者预期的要好
在人们开始摆弄 GPT-3 之前,笔者已经更新了笔者的时间轴估计,但 GPT-3 是促使笔者写下本文解释原因的动机。
笔者们在 GPT-3 上看到的是,语言是一个非常灵活的输入空间。人们早就知道这一点了。笔者认识一位从事自然语言处理的教授,他说,语言理解是一项人工智能完成的任务,因为一台假设的机器完全理解并且回答所有的问题,就像人类一样。也有人认为,压缩是智能的代表。正如 Hutter Prize 网站上所论述的那样,要压缩数据,就必须识别数据中的模式,如果你把模式识别看作是智能的一个关键组成部分,那么更好的压缩器应该更智能。
需要说明的是,这些并不是自然语言处理研究界的普遍观点!关于 语言理解究竟意味着什么 这一问题,人们展开了激烈的争论。笔者之所以提到它们,是因为这些观点都是严肃的人所持有的,而 GPT-3 的结果支持这些观点。
GPT-3 有很多东西,但它的核心是一个系统,它使用大量的训练时间,将一个非常大的文本预料压缩成一组较小的 Transformer>) 权重。最终的结果展示了一个令人惊讶的知识广度,可以缩小到许多不同的任务中,只要你能将这个任务变成文本的提示,以种子模型的输出。它是有缺陷,但技术演示的广度是有点荒谬的。同样值得注意的是,大多数这种行为都是由于善于预测文本的下一个标记而产生的。
这个成功是上一节(更好的无监督学习)的一个具体例子,也是第一部分(更好的工具)的标志。尽管在故事生成中有很多有趣的东西,但笔者最感兴趣的是 代码生成演示。它们看起来就像是“Do What I Mean”编程接口的早期迹象。
这太让人兴奋了。使用 GPT-3,笔者构建了一个布局生成器,你只需在其中描述任何你想要的布局,它就会为你生成 JSX 代码。
如果现有的技术演示可以提高 5 倍,那么,如果它们变成了具体细节变成的关键生产力助推器,笔者也不会感到惊讶。目前,系统设计、代码验证和调试很可能都是由人工来完成的,但很多编程都是在代码内“着色”。即使是低水平的功能也可能会改变游戏规则,就像 2000 年前的搜索引擎一样。AltaVista 在 1998 年的访问量排名第 11,肯定比 Google/Bing/DuckDuckGo 现在能做的还要糟糕。
笔者们可以看到,代码生成有用的一个具体方式是用于机器学习工作。比如 神经结构搜索 和 黑盒超参数优化。围绕通用人工智能的常见争论之一是 智能爆炸,而这类黑盒方法被视为一种潜在的智能爆炸机制。但是,它们长期以来一直存在一个关键的限制:即使你假定计算量是无限的,也必须有人实现代码,从实验参数到最终性能提供一个干净 API。可探索的搜索空间从根本上受到人类所认为的搜索空间维度的限制。如果你不设想搜索空间的一部分,机器学习就不能对它进行探索。
机器人学习中的域随机化也存在同样的问题。这是笔者对 OpenAI Rubik Cube 结果 的主要批评。这篇论文读起来像是一年来对 Rubik Cube 域随机化搜索空间的发现,而不是任何可泛化的机器人学习课程。最终的结果是基于一个从大量随机模拟中学习泛化的模型,但这个模型之所以能达到这个效果,是因为人们花费了大量的精力来确定哪些随机化值得实施。
现在想象一下,每当你在模拟器中发现一个未知的新未知时,你可以非常快速地实现代码的更改,将它添加到你的域随机化搜索空间。嗯,这些方法看起来确实比较有前途。
GPT-3 当然也存在一些问题。它有一个固定的注意力窗口。它没有办法从试图预测下一个文本字符的过程中学习任何它还没有学到的东西。要确定它知道什么,需要学习如何提示 GPT-3 给出你想要的输出,而不是所有简单的提示都能奏效。最后,它没有意图或代理的概念。它就是下一个词的预测器。这就是它的全部,笔者猜想,试图改变它的训练损失以增加意图或代理,将比听起来要困难得多。(而在笔者看来已经相当困难了!永远不要低估一个工作中的机器学习研究项目的惯性。)
但是,这又一次让笔者想起了很多早期的搜索引擎。当笔者还是个孩子的时候,为了让更好的搜索结果出现的频率更高,笔者被教导如何组织搜索查询关键词。要避免使用简短的词,将重要的关键词放在前面,不要输入完整的句子。笔者们之所以这样处理,是因为它的收益是值得的。GPT-3 可能与之类似。
笔者现在期望计算将发挥更大的作用,并看到模型的发展空间
出于笔者不想在本文中谈及的原因,笔者不喜欢这样的论点,即人们对人脑进行计算估计,采用摩尔定律曲线,推断出这两条曲线,然后宣布通用人工智能将在两条曲线相交时发生。笔者认为他们把讨论过于简单化了。
然而,不可否认的是,在机器学习进程中,计算扮演着重要的角色。但人工智能的能力有多少是由更好的硬件让笔者们扩展现有模型驱动的,又有多少是由新的机器学习理念驱动的呢?这是一个复杂的问题,特别是因为两者并非独立的。新的想法可以让硬件得到更好的利用,而更多的硬件可以让你尝试更多的想法。笔者在 2015 年对这种可怕的简化的猜测是,通用人工智能进步的 50% 将来自计算,50% 将来自更好的算法。在 2015 年的模型之间缺失了几样东西,还有一些东西将“通用”放在了通用人工智能中。笔者不相信依靠更多的计算能解决这个问题。
从那以后,有很多成功的例子都是由扩大模型来实现的,笔者现在认为这个平衡更像是 65% 的计算,35% 的算法。笔者怀疑许多类似人类的学习行为可能只是更大模型的突显特性。笔者还怀疑,许多人类认为是“智能的”、“有意的”事物,其实都不是。笔者们只是想认为自己是聪明的、有意识的。笔者们不是,机器学习模型需要跨越的门槛也没有笔者们想象的那么高。
如果计算发挥了更大的作用,那么时间轴就会加快。机器学习理念的瓶颈是机器学习社区的规模和发展,而更快的硬件是由全球消费者对硬件的需求推动的。后者是一股更强大的力量。
让笔者们先回到 GPT-3。GPT-3 并不是你可以构造最大的 Transformer,因此,有理由建造更大的 Transformer。如果将大型 Transformer 的性能标度为 2 数量级(15 亿个参数用于 GPT-2,1750 亿个参数用于 GPT-3),那么再标度为 2 数量级也不会太奇怪。当然,也可能不会。(Kaplan 等人,2020 年)标度律应该从参数 $10^{12}$ 开始相互矛盾。这与 GPT-3 相差不到 1 个数量级。不过,这并不意味着该模式将停止改进。这只是意味着它会以不同的速度提高。笔者不认为有什么好的理由可以证明笔者们应该相信一个 100 倍的模型在质量上不会有什么不同。
尤其是你转向多模态学习(multi-modal learning)的时候,更是如此。专注于 GPT-3 的文本生成是遗漏了主要的情节线程。如果你相信 传言,OpenAI 一直致力于将音频和视频数据纳入他们的大型模型中。到目前为止,他们的研究产出与此一致。MuseNet 是一个基于大型 Transformer 的音频生成模型。最近的 Image GPT 是针对图像的生成模型,也是基于大型 Transformer 的。
MuseNet 问世时,是不是当时最先进的音频合成技术?不是。Image GPT 是图像生成的最新技术吗?也不是。专门针对音频和图像生成的模型架构比 MuseNet 和 Image GPT 做得更好。若专注于这一点,就忽略了 OpenAI 所要表达的观点:一个足够大的 Transformer 并非最先进的,但它在这些截然不同的数据格式上做得足够好。还有比 MuseNet 更好的模型,但它仍然足够支持一些愚蠢但也许有用的音频完成。
如果你已经证明一个大型 Transformer 可以单独处理音频、图像和文本,为什么不去试试同时对这三个进行测试呢?据推测,如果所有的模态都经过类似的神经网络架构,大概这种多模态学习将会更容易,而他们的研究表明,Transformer 的工作足以成为这种架构。
OpenAI 可以利用他们已经拥有的关于大型 Transformer 的任何直觉,这一点很有帮助。一旦加入其他数据流,肯定会有足够的数据来训练更大的无监督模型。当然,你也可以只使用文本,但你也可以使用所有的网络文本,所有的视频和所有的音频。只要你能够扩展到足够大的规模,就不应该有什么取舍。
大型 Transformer 会是笔者们将使用的最后一个模型架构吗?不,也许不是。它们目前的一些弱点似乎难以解决。但笔者确实看到了它们的发展空间,可以做得比目前更多。模型架构只会越来越好,所以扩展现有模型的能力一定是 10 年或 20 年后,更强的模型架构的扩展版本所能实现的下限。现在可能发生的事情已经很有趣了,但也略微让人担忧。
整体局势
在“You and Your Research”(《你和你的研究》中,Richard Hamming 曾提出一条著名的建议:“你所在的领域中,重要问题是什么?为什么你不去研究它们?”当然,通用人工智能是机器学习最重要的问题之一。
那么,对于机器学习来说,这个问题的自然版本是,“需要解决哪些问题,才能实现通用人工智能?”你希望这个领域在到达那里的路上会遇到哪些路标,这些路标之间的路径有多少不确定性?
笔者觉得更多的路标开始成为焦点。如果你问 2015 年的笔者,笔者们将如何开发通用人工智能?笔者会告诉你,笔者根本就不知道怎么弄。在笔者认为与人类智力水平有关的任何挑战上,笔者不认为笔者们取得了什么有意义的进展。但是,如果你问 2020 年的笔者,如何开发通用人工智能,尽管笔者仍然看到很大的差距,假设你很幸运,笔者对如何实现通用人工智能有所了解。这对笔者来说是最大的转变。
对于大规模统计机器学习对人工智能的意义,人们一直存在分歧。深度学习的反对者不能否认大型统计机器学习模型非常有用,但深度学习的拥护者也不能否认它们非常昂贵。指出最先进的模型需要多少计算量,这是一个悠久的传统。来看看这张照片,在李世石在与 AlphaGo 比赛围棋时,就在 Twitter 上流转开来了。

像这样的论点很好地将讨论引向模型与人类相比不足之处,并且戳中笔者们现有的模型可能存在的根本性缺陷,但笔者觉得这些论点还是过于以人为中心了。笔者们对人类如何学习的理解还不完全,但笔者们还是接管了这个星球。同样,笔者们不需要对“理解”或“知识”的含义达成细粒度上的一致,人工智能系统就能对世界产生深远的影响。笔者们也不必打造像人类一样学习的人工智能系统。如果它们能够完成大多数人类水平的任务,那么剩下的工作就是由经济学来完成,不管这些系统是否是按照笔者们自己的形象制造的。
竭力拒绝
关于通用人工智能的争论总是有点混乱,因为人们在重要的事情上,有着迥然不同的信念。一个有用的做法是,假设通用人工智能在短期内是可能的,确定在那个假设的未来可能是真实的,然后评估它听起来是否合理。
这与提出通用人工智能不可能发生的理由是截然不同的,因为有很多理由说明通用人工智能不会出现。但是,为什么会出现通用人工智能,也有大量的理由。这项练习是要把更多精力放在后者上,并且看看对所有事情都说“No”是多么的困难。这有助于你将注意力集中在真正重要的论点上。
让笔者试试看吧。如果通用人工智能很快成为可能的话,这可能会如何发生呢?嗯,这不需要更多的新想法。它很可能是基于现有模型的扩展,因为笔者认为,该领域没有太多时间进行全面的范式转换。而且,它还需要大量的资金,因为它需要基于规模化,而规模化需要资金。
也许有人开发了一个应用或工具什么的,使用的模型是 GPT-3 的尺寸或更大的尺寸,那是一个巨大的生产力倍增器。想象一下,第一台计算机、Lotus Notes 或 Microsoft Excel 是怎么接管商业世界的。记住,是工具推动了进步!如果你的代码速度加快 2 倍,那可能就是研究产出的 1.5 倍。上移或下移取决于实现过程中遇到瓶颈的频率。
如果这种生产力的提升有足够的价值,使经济效益得以实现,而且一旦考虑推理和训练成本,就能赚取净利润,那么就有生意可做了:从字面上说,大公司为你的工具买单。向客户付费会带动更多的资金和投资,从而为更多的硬件买单,从而使训练规模更大。在云计算中,你购买多余的硬件来预测消费者需求的激增,然后出售对额外硬件的访问权来赚钱。在这种情况下,你购买多余的硬件来预测消费者推理需求的峰值,然后将多余的算力提供给研究人员,看看他们会得出什么结果。
这种机制已经开始发挥作用了。你可能认得下图所示的芯片。

上图是第一个 TPU 的照片,正如 [Google 博客')(https://cloud.google.com/blog/products/gcp/an-in-depth-look-at-googles-first-tensor-processing-unit-tpu) 中解释的那样:
尽管 Google 早在 2006 年就考虑为神经网络打造特殊应用集成电路(Application-Specific Integrated Circuit,ASIC),但在 2013 年,情况变得紧迫起来。这时笔者们才意识到,神经网络快速增长的计算需求可能需要笔者们将运营的数据中心数量增加一倍。
Google 需要在生产中运行更多的神经网络。这带动了更多的硬件投资。几年后,笔者们现在发展到了 TPU v3,有传言称,Facebook 正在招聘人员为 AR 技术定制芯片。因此,硬件需求的故事不仅仅是可信的,而且很可能是真实的。如果你可以扩展到做一些不切实际的事情,那么就会激发研究和需求,使其变得切实可行。
在此基础上,笔者们假设跨模态学习结果比预期的规模化学习更容易。与 GPT-3 相似的涌现性出现了。目标跟踪和 物理直觉 被证明是自然发生的现象,只需从图像中学习,不需要直接的环境交互或体现。通过更多的调整,更大的模型,甚至更多的数据,你最终会得到一个丰富的图像。文本和音频的特征空间。从头开始训练任何同喜很快就会变得不可思议。你为什么要这样做?
在几个领域中,先前的大部分工作都已经过时了,如视觉的 SIFT 特征、机器翻译的 分析树,以及语音识别的 音素 解码步骤等。深度学习已经扼杀了这些方法。那些对这些技术一无所知的人正在研究神经网络,在这三个领域都取得了最先进的成果。这有点让人感到难过,因为有些过时的想法,确实对笔者们理解语言和语音的方式进行了很酷的分解,但事实就是如此。
随着模型变得越来越大,并不断显示出改进的性能,研究结合了一部分方法,这些方法已被证明可通过计算进行扩展。同样,这种情况在深度学习中也发生过,并且仍然在发生。当许多领域使用同一套技术时,你会得到更多的知识共享,这将推动更好的研究。CNN 对于考虑临近值有很强的先验性。它们最初用于图像识别,但现在对基因组学(Nature Genetics,2019 年),以及音乐生成(van den Oord 等人,2016 年)都有影响。Transformer 是一种序列模型,最早用于语言建模。后来它们被用于视频理解(Sun 等人,2019 年)。这种趋势可能还会继续下去。机器学习已经达到了这样的一个地步,将某件事物描述为“深度学习”实际上是没哟爻的,因为多层感知已经与足够多的领域结合在一起,你无需在指定任何东西。也许过五年以后,笔者们会有一个新的流行词取代“深度学习”。
如果这个模型擅长语言、语音和视觉数据,那么,人类有哪些“传感器”输入是这个模型所没有的?无非就是与物理化体现挂钩的传感器,比如味觉、触觉等。笔者们能说智能在这些刺激上遇到了瓶颈吗?当然可以,但笔者却不认为是这样。你可以说只需要文字就可以假装成人类。
在上述的场景中,有很多事情要做好。多模态学习必须奏效。行为需要继续从规模扩展中出现,因为研究人员的时间主要是投入到帮助你实现规模化的想法中,而不是归纳先验。硬件效率必须与时俱进,这包括清洁能源发电和修复不断增加的硬件集群。总的来说,必须要做好的事情很多,这让笔者觉得不太可能,但还是有值得认真对待的可能性。
笔者在笔者的故事中看到最有可能的问题是,对于语言以外的任何东西,无监督学习可能会更加困难。记住,在 2015 年,无监督学习为笔者们提供了用于语言的词向量,而对于图像却没有取得什么好的成绩。一个合理的假设是,语言的组合特性使得它非常适合于无监督学习,而这在其他输入模式中是不适用的。如果这是真的,笔者可能因为过分关注成功而高估了研究。
正式由于这些原因,笔者只是将笔者的估计调整了几年。笔者并不认为 GPT-3 本身就是一个从根本上调整笔者所认为是可能的。笔者认为迁移学习比预期的要难也是一个障碍。但在网上,笔者看到的大多数理由都是加速笔者的估计,而不是放慢它们。
以上是有关通用人工智能什么时候实现的相关内容,希望对伙伴们有所帮助,想要了解更多资讯,请继续关注可圈可点网站。